I am excited to announce that my thesis, "I Want Sin: Finding Personhood Amidst Technology in Young Adult Dystopian Literature," has been completed and is available to be viewed below! This process has been stressful, tiring, exciting, and edifying, and I am proud of the final product that has been produced. I am also excited to close the several hundred tabs that have been open on my laptop for the past 5 months.
Please check out my work below:
Thursday, May 10, 2018
Wednesday, February 28, 2018
Progress and challenges
In the past month, I have summarized and written the bulk of my sections on Extras, The Adoration of Jenna Fox, and Feed. Although I wanted to be done with all of this by the end of February, I only have two books left to review, Uglies and Ender's Game, and I feel that I'm in a pretty good place. Most of these works will average about ten pages, although Uglies will technically address three books, and will likely be the longest section.
Right now, I'm just writing, just drafting. I'm working through how I want to approach this paper. The main point of my work is the value of humanity, which is threatened by various technological implementations throughout the books I have selected. Although some of this can be attributed to transhumanism, not all of it is, which has been interesting for me, I'm certainly still referencing trans and posthumanism, but the technological aspect has gotten wider. I've begun to call the technological influences in my books "Radical Transformative Technology," which I believe well encompasses transhumanism, posthumanism, and everything before and in-between.
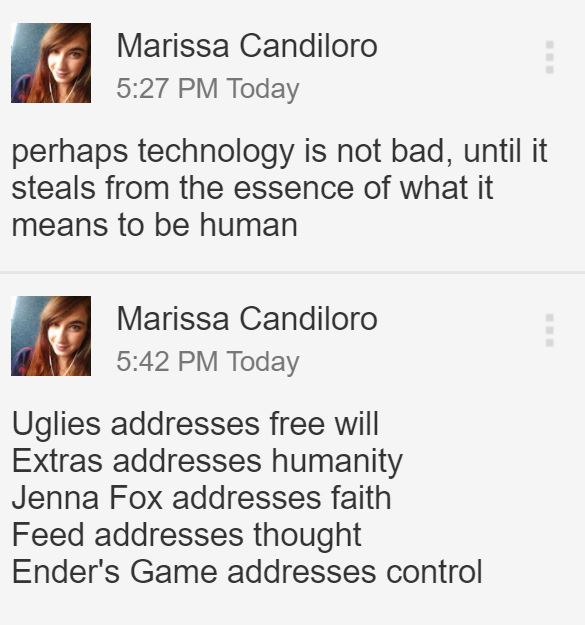
I've discovered that each book teaches different things regarding the importance of humanity, which has become the real purpose of my thesis. Feed teaches the importance of free thought. The Adoration of Jenna Fox address faith. Extras addresses the mistakes that accompany free will. Uglies addresses _______(I want to say "control," but I need a better word). Ender's Game addresses manipulation. In all of these themes, humanity is the uniting force, and can see the strands that link each work. When any kind of radical transformative technology is implemented, humanity suffers.
Interestingly, to me, The Adoration of Jenna Fox has been the hardest work for me to write about. I wrote about eight pages and stopped. The issue of faith has been challenging to address, however I believe it is crucial to my topic. I am a devout Christian, I believe that every human being has worth because they are God's creation and, when I look at transhumanism and posthumanism, I see potential threats to the sanctity of life. I can certainly make most of my arguments against radical transformative technology without getting into Christianity, and most of the works I have chosen have a non-religious base, but Jenna Fox is intrinsically tied to Christianity. For this reason, I think faith is something that should be considered. After all, it is an important element of many people's lives, and is arguably as important as free will and free thought. I have plenty of academic sources to back up what I want to say, but it's been challenging.
I'm still seeing where this is all going. Right now, I'm still happy. I think my thought process is doing just fine.
Right now, I'm just writing, just drafting. I'm working through how I want to approach this paper. The main point of my work is the value of humanity, which is threatened by various technological implementations throughout the books I have selected. Although some of this can be attributed to transhumanism, not all of it is, which has been interesting for me, I'm certainly still referencing trans and posthumanism, but the technological aspect has gotten wider. I've begun to call the technological influences in my books "Radical Transformative Technology," which I believe well encompasses transhumanism, posthumanism, and everything before and in-between.
I've discovered that each book teaches different things regarding the importance of humanity, which has become the real purpose of my thesis. Feed teaches the importance of free thought. The Adoration of Jenna Fox address faith. Extras addresses the mistakes that accompany free will. Uglies addresses _______(I want to say "control," but I need a better word). Ender's Game addresses manipulation. In all of these themes, humanity is the uniting force, and can see the strands that link each work. When any kind of radical transformative technology is implemented, humanity suffers.
Interestingly, to me, The Adoration of Jenna Fox has been the hardest work for me to write about. I wrote about eight pages and stopped. The issue of faith has been challenging to address, however I believe it is crucial to my topic. I am a devout Christian, I believe that every human being has worth because they are God's creation and, when I look at transhumanism and posthumanism, I see potential threats to the sanctity of life. I can certainly make most of my arguments against radical transformative technology without getting into Christianity, and most of the works I have chosen have a non-religious base, but Jenna Fox is intrinsically tied to Christianity. For this reason, I think faith is something that should be considered. After all, it is an important element of many people's lives, and is arguably as important as free will and free thought. I have plenty of academic sources to back up what I want to say, but it's been challenging.
I'm still seeing where this is all going. Right now, I'm still happy. I think my thought process is doing just fine.
Saturday, February 17, 2018
Ideas Transforming
Throwing a few screenshots up to show how, when I write, I have conversations with myself in comment form. Every time I write, my thesis changes a little bit-- which is excellent, and I learn a little more about what I think about my own ideas. Even if it's not yet clear to others, I see the strands beginning to take form and it makes me very happy.


On a side note, yes it is a Saturday night, and yes I am doing work. My friends and my fiance will be quite happy when this is all over, because "you're always working, you're never around." Oops.

On a side note, yes it is a Saturday night, and yes I am doing work. My friends and my fiance will be quite happy when this is all over, because "you're always working, you're never around." Oops.
Thursday, February 8, 2018
Reading
This week, I've been working through How We Became Posthuman by N. Katherine Hayles, which is a key book in the field of posthumanism. Some of it relates to literature but, for the most part, it is a history of society's interest in technologically advanced humanity. I must admit, some of it is very dry, but it is fascinating and I'm happy to be reading the book in the field that all of the other books and articles cite. Next on my reading list is Our Posthuman Future by Francis Fukuyama.
The next portion of my thesis that I hope to knock off is the Lit Review portion-- the sooner the better!
The next portion of my thesis that I hope to knock off is the Lit Review portion-- the sooner the better!
Oops I forgot to blog last week....
So here's catching up. Last week, I wrote a portion of my Methods section and sent it to Alan, who gave me helpful feedback. I haven't updated it yet because I've been working on other stuff (see next blog). But anyway, here's a link to the Methods section in progress:
https://docs.google.com/document/d/1zqI-w7rFU7BzD3BEYoe0mfNSEbUxBIVv3HAfQGNlh_A/edit?usp=sharing
https://docs.google.com/document/d/1zqI-w7rFU7BzD3BEYoe0mfNSEbUxBIVv3HAfQGNlh_A/edit?usp=sharing
Tuesday, January 23, 2018
Research
This week, I've been doing background reading for my thesis. I discovered an audio book on Audible from The Great Courses, called Great Utopian and Dystopian Works of Literature, led by Dr. Pamela Bedore from the University of Conneticut. This audio book has been an unexpectedly great resources, and it's exciting to be listening to university lectures on my favorite topic. I've also gotten a few new ideas from it-- namely, the short story "The Ones Who Walk Away From Omelas" by Ursula K. LeGuin.
I've also been reading Technology and Identity in Young Adult Literature Fiction: The Posthuman Subject by Victoria Flanagan, which adds an interesting (and important) dimension to my research, because I totally disagree with most of her views. She purports that posthumanism can be used to enhance the human subject, which goes directly against my views on the matter. It's funny, because we've read most of the same books, but have come away with completely different impressions. Even so, it's good to see both sides of an issue, and I'm quite interested to hear what she has to say.
I also bought and am waiting to receive four physical copies of books which, prior to now, I've only had PDFs of on my computer.
That's all I have for now, but I'll check in periodically, or if anything interesting comes up!
I've also been reading Technology and Identity in Young Adult Literature Fiction: The Posthuman Subject by Victoria Flanagan, which adds an interesting (and important) dimension to my research, because I totally disagree with most of her views. She purports that posthumanism can be used to enhance the human subject, which goes directly against my views on the matter. It's funny, because we've read most of the same books, but have come away with completely different impressions. Even so, it's good to see both sides of an issue, and I'm quite interested to hear what she has to say.
I also bought and am waiting to receive four physical copies of books which, prior to now, I've only had PDFs of on my computer.
That's all I have for now, but I'll check in periodically, or if anything interesting comes up!
Thursday, December 14, 2017
Link to Intro & Outline
My intro is kinda a trainwreck right now, so I'm going to share the link to it, rather than posting my segmented ramblings here.
Working intro.
Personally, I'm more excited about the outline I drew up last night, so maybe this is a little more interesting to the viewer?
Outline.
Personally, I'm more excited about the outline I drew up last night, so maybe this is a little more interesting to the viewer?
Outline.
Tuesday, December 12, 2017
Working Thesis Title
The (Trans)humanism of Young Adult Literature: Exploring the Shortsighted Nature of Transhumanism Through the Scope of Youth
Sources Galore
As I mentioned last class, I received a lot of sources from an unlikely person-- the pastor of my church. Every year, he does a series called "The God Questions" where he brings up topical issues in the world right now, and teaches the Christian approach to such challenges. My pastor is a former teacher, and a doctor, so I hold his academic opinion in high esteem. A few weeks ago, he spoke on transhumanism (imagine my surprise), and the idea of the "humanity" of AI-- and all during the service I scribbled down books he mentioned that would be helpful to my research. I spoke with him after the service, and he sent me four emails full of links and slides from his sermon, and I am quite grateful
Honestly, I'm not much of a planner. I think I know where this topic is going, but I could be surprised. I usually begin to sort things out as a write and, right now, I'm probably not going to get too spiritual with my topic, although the idea of humanity and humanism is deeply spiritual. Regardless, I think I will be able to use several of these sources.
Honestly, I'm not much of a planner. I think I know where this topic is going, but I could be surprised. I usually begin to sort things out as a write and, right now, I'm probably not going to get too spiritual with my topic, although the idea of humanity and humanism is deeply spiritual. Regardless, I think I will be able to use several of these sources.
Thursday, December 7, 2017
Evernote library

I scrapped all of the research for my old idea-- see "Trash (33)," and reformatted my folders and tags to fit my new thesis. It's been quite helpful!
Wednesday, November 22, 2017
Ideas!
I'm moving again, and I'm happy about it! I don't particularly want to take much time blogging now, because my limited time needs to be spent researching, but an update is in order.
In the past week, I've spoken with a professor from my undergrad, as well as with my boss at the Kean Writing Project, Kim Kiefer, who is a high school English teacher. Between those two conversations, I'm excited to write this thesis.
In my discussion with Kim, we talked about my interest in the YA hero, and discussed using The Hero With A Thousand Faces by Joseph Campbell, as one of my primary texts, as a way to analyze the hero's journey through the books I am interested in discussing (a list that I will explain later in this post). I have never read this book personally, although it has been discussed in many courses I have taken, and I am interested to see if it helps to guide my research. (note-- after writing this sentence, I remembered that Kean has a library and promptly walked over and checked it out)
 |
| Proof that I went to the library. Not pictured-- the spine falling off the book |
In addition to this book, Kim also suggested that I read into Jungian archetypes as a way of discussing my heroes. I don't know much about Carl Jung outside of the Myers-Briggs personality test, so this is something I will have to research further. However, a baseline Google search brought this list to my attention. Of course, I will find a better primary source to use in my work.
Okay so, heroes and YA literature. That's still pretty broad. This is where my conversation with Dr. Hogsette (aforementioned undergrad prof) helped me further.
In my senior year of college, I was in Dr. Hogsette's Science Fiction Literature class, and he talked a lot about the ideas of transhumanism and posthumanism in science fiction. Transhumanism and posthumanism are two tropes that are commonly used in utopian literature, as ways of proving that humanity can be so much more than it currently is, through the integration of technology. However, even though these ideas are usually presented positively, the stories ultimately warn that "all that glitters is not gold"-- or, perhaps, all that has circuits is not better than flesh and blood? Usually, these lessons come in the way of a utopian world turning into a dystopian nightmare.
I have to read more about trans and posthumanism to refresh my memory of their respective intricacies, but my professor gave me a ton of sources to look into including:
How We Became Posthuman: Virtual Bodies in Cybernetics, Literature, and Informatics by N. Katherine Hayles
Prophets of the Posthuman: American Fiction, Biotechnology, and the Ethics of Personhood by Christina Bieber Lake
Our Posthuman Future: Consequences of the Biotechnology Revolution by Francis Fukuyama
Technology and Identity in Young Adult Fiction: The Posthuman Subject" by Victoria Flanagan
In considering all of the dystopian books I have read, there are a handful that I can think of that work with this idea. Right now, my list includes:
Uglies
Pretties
Specials
-by Scott Westerfeld
The Giver by Lois Lowry
Feed by M.T. Anderson
The Adoration of Jenna Fox by Mary E. Pearson
The City of Ember by Jeanne Duprau
Life As We Knew It by Susan Beth Pfeffer (this one is still on the "to-read" list, but I'm reasonably sure it will fit the topic)
In all of these books, the characters, or their world has been altered for some specific technological end, and the protagonists have to deal with the implications of these changes. Ultimately, what the world-builders hoped would lead to utopia, has instead led to dystopia, and we are left with the question of-- why are we searching to perfect mankind through technology? Are we ultimately better for it? Have we reached the ultimate moral nirvana? Signs point to no.
Finally-- why the YA lit focus? Simply, because I like it. Maybe I'll discover some kind of theory as to why kids are into these books...and maybe not. We'll see where the research takes me.
Subscribe to:
Posts (Atom)
-
Happy Wednesday everyone! So, today I come to the research and Digital Humanities communities looking for help/direction with my thesis wo...
-
 Hello again, readers. Let me start this blog off by saying that I am so grateful for the responses generated by last week's post! I rece...
Hello again, readers. Let me start this blog off by saying that I am so grateful for the responses generated by last week's post! I rece...