In these next few weeks, my plan is to use my blog posts to explore programs that I am considering using in my thesis work and, since I'm already familiar with Voyant and Hypothes.is, I'm going to start this week by researching Google Ngram.
In one conversation between Alan and myself, the topic of accessibility came up, and we tossed around the issue of how to determine if a tool is reasonably easy to learn. Between myself and my target group, few DH newcomers are going to have the time or expertise to learn the more complicated programs. As I discover tools that I'm interested in using, I'm going to have to come with with an accessibility scale, in order to determine the level of difficulty at which to rank each individual tool. I'm not entirely sure how I'm going to do this yet, but right now my standard is simple-- can Google teach me?
Not knowing much about Ngram, I decided to do as all good students do, and immediately check Wikipedia (I'm getting my Masters degree and it hasn't failed me yet, alright?). Here's how Wikipedia describes the tool:
An online search engine that charts frequencies of any set of comma-delimited search strings using a yearly count of n-grams found in sources printed between 1500 and 2008 in Google's text corpora in English, Chinese (simplified), French, German, Hebrew, Italian, Russian, or Spanish; there are also some specialized English corpora, such as American English, British English, English Fiction, and English One Million; the 2009 version of most corpora is also available.
The program can search for a single word or a phrase, including misspellings or gibberish. The n-grams are matched with the text within the selected corpus, optionally using case-sensitive spelling (which compares the exact use of uppercase letters), and, if found in 40 or more books, are then plotted on a graph.This seems to be quite a powerful tool! What interested me most in this blurb is that the search engine has been programmed to work with such an amazingly large corpus. Although much modern work is still within copyright, it's amazing to be that one program can harness books written over the course of 500 years-- that's astronomical! From this alone, it seems that Ngram will be quite useful to my work.
My next step was to Google "Google Ngram tutorial" and see what I could learn. The first result seemed helpful, so I clicked and this is what I found.
Following the instructions on the webpage, I went to Ngram viewer, typed in a few phrases, and chose a time frame. Because I'm sticking with my dystopian literature theme, I tried to use phrases that I thought would lead to helpful results, and made my time frame span from 1850 to 2000.
The following screen grab shows my results from messing around a bit with the program. It's quite interesting, although I'm surprised that my keywords aren't more successful-- although maybe I'm just not understanding the results. I'm going to tweet out the link to my blog and see if anyone with more knowledge of Ngram responds.
Here are the results from my first searches:
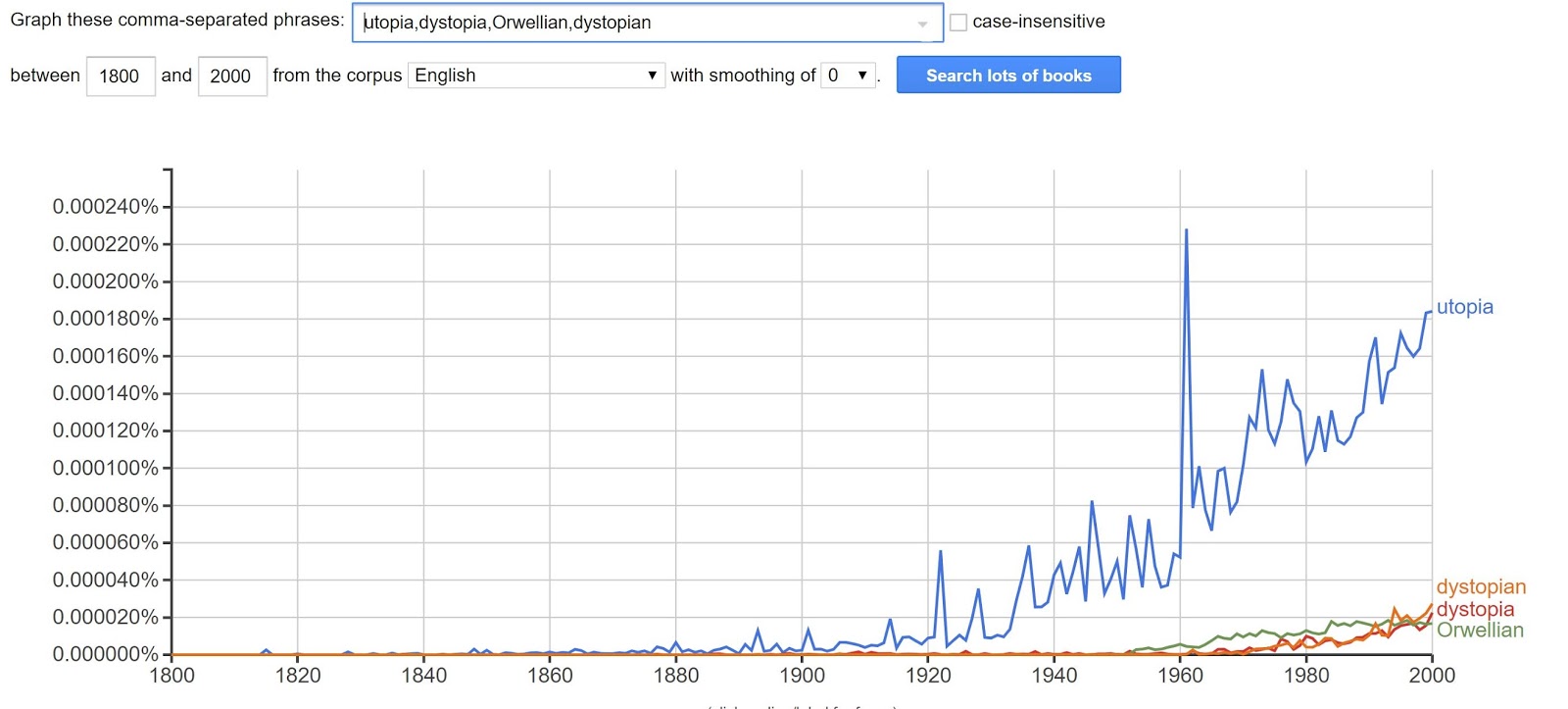
Just from these results, it's interesting to me that the phrase "utopia" spiked in the 1960s, and this is the kind of thing that would lead research questions. In the case of a high school student, this could be a spark that would lead to research for a paper topic. Already, there are good, useful reasons for a teacher to delve into this program.
Lifewire (see above link) also had helpful information for drilling down into more specific tag related searches, which I tried with the search term "Big Brother_NOUN" -- as to differentiate Orwell's all-seeing government from books about familial relations.
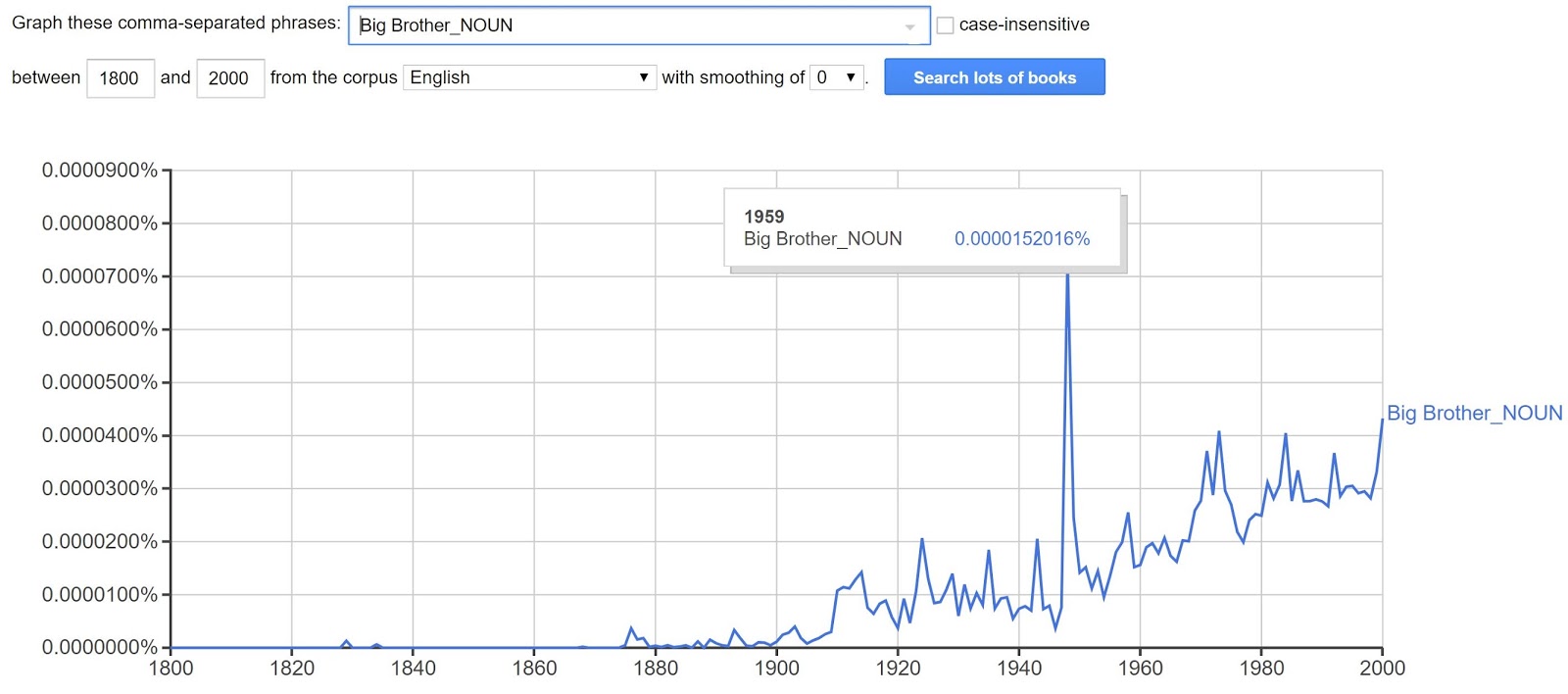
How cool is this?? 1984 was published in 1949 and, low and behold, the term spiked around that time period, before dropping off and slowly climbing again. So interesting!
I decided to play around a bit more, and in doing so I found another cool use of the tags feature. I searched "Orwellian" earlier and was less than impressed with the search results. However, this time around I searched "Orwellian_NOUN" and found much more to talk about. Quite interesting how the term has spiked in use in the past 30+ years...

In my browsing, I also found that Google's Ngram help page was useful in picking up some more tips and tricks about the program, such as the following search enhancers:
 |
| So much to learn! So much power to harness! |
From Google's help page, I learned about the => modifier tag, which tracks term dependencies. For example, on the page the writer explains how the word "tasty" often modifies the word "dessert," there one might search tasty=>dessert. For my purposes I searched utopian=>society:

Strangely, I couldn't find significant results for "dystopian=>society" but the search continues!
Luckily, I had success in my search for "dystopia" as the root of the sentence in this next example, in which I obtained results via the comment _ROOT_=>dystopia. As you can see: in 1994-1995, the topic of dystopia spiked:

Another command recommended by the Ngram info page was [entry]=>*_NOUN, which takes the entry you put in, and uses the * in order to fill in the top ten noun substitutions for the search. For example, I searched utopia=>*_NOUN and my results showed:

As you can see in this graph, the top ranking results is "utopia=>Morris", which spiked in 1977. Who's Morris? I have no idea, but this is the reason that this program is great for research!
Here are some more results for dystopia=>*_NOUN, with the graph settings adjusted slightly:

If you can't tell, I am extremely excited by this adventure into Ngram and am quite hopeful that this will be excellent for my thesis work!
---
*Semi-unrelated aside:
Although my thesis work is based in literature, I was interested in the implications of using Ngram to track the intricacies of language. The very first sentence of the Lifewire link reads:
"A Ngram, also commonly called an N-gram is a statistical analysis of text or speech content to find n (a number) of some sort of item in the text. It could be all sorts of things, like phonemes, prefixes, phrases, or letters.""Phonemes, prefixes" caught my interest immediately. Outside of literature, I am incredible interested in phonetics and the sounds and pronunciations that make up English, among other languages. Ngram may prove to be useful to me in other areas in my life, it would be cool to see how it could be used to trace language throughout the years. The above-mentioned Google link also had a great deal of information regarding how the program might be used to track language trends. Excuse the aside, but that's what I love about research and learning, you're never done falling down new rabbit holes!
No comments:
Post a Comment